- Xue Yang, Shanghai Jiao Tong University, China
- Junchi Yan (corresponding author), Shanghai Jiao Tong University, China
Object Heading Detection Dataset (OHD-SJTU)
Data Description
Data Description
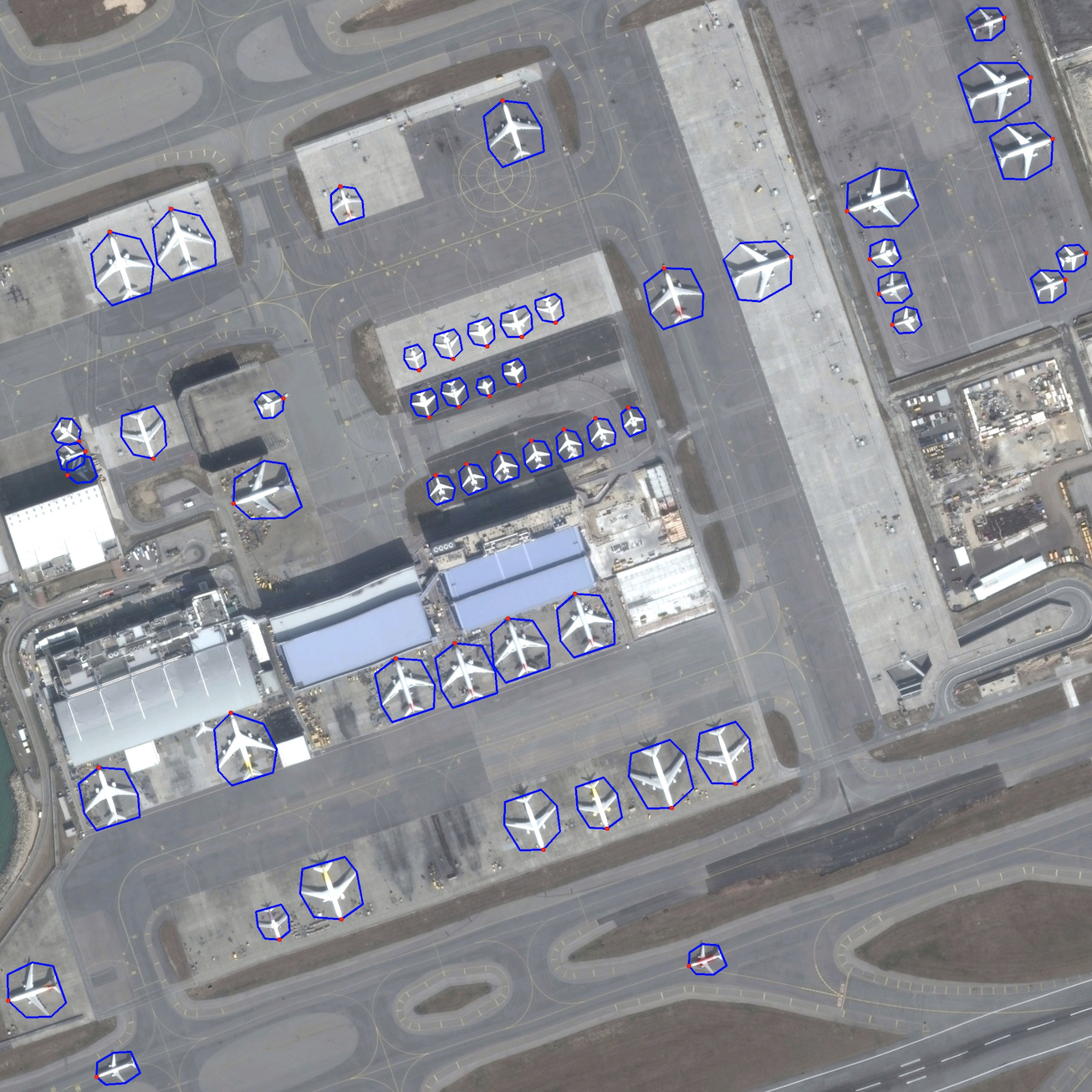
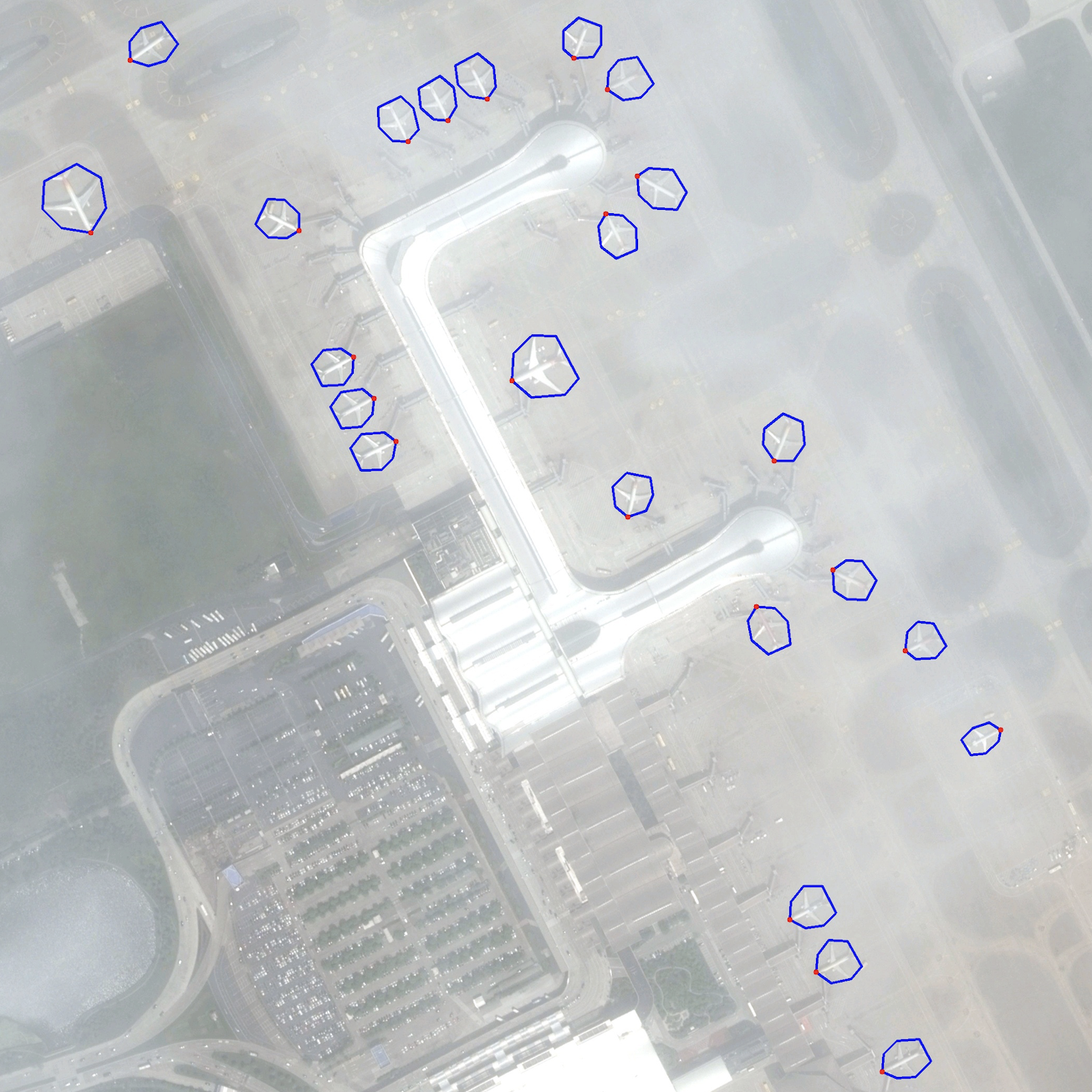
OHD-SJTU is our open source new dataset for rotation detection and object heading detection. OHD-SJTU contains two different scale datasets, namely OHD-SJTU-S and OHD-SJTU-L. OHD-SJTU-S is collected publicly from Google Earth with 43 large scene images sized 10,000x10,000 pixels and 16,000x16,000. It contains two object categories (ship and plane) and 4125 instances (3,343 ships and 782 planes). Each object is labeled by an arbitrary quadrilateral, and the first marked point is the head position of the object to facilitate the head prediction. We randomly selected 30 original images as the training and validation set, and 13 images as the testing set. The scenes cover a decent variety of road scenes and typical: cloud occlusion, seamless dense arrangement, strong changes in illumination/exposure, mixed sea and land scenes and large number of interfering objects. In contrast, OHD-SJTU-L adds more categories on the basis of OHD-SJTU-S, such as small vehicle, large vehicle, harbor, and helicopter. The additional data comes from DOTA, but we reprocess the annotations and add the annotations of the object head. According to statistics, OHD-SJTU-L contains six object categories and 113,435 instances. Compared with the AP50 used by DOTA as the evaluation indicator, OHD-SJTU uses a more stringent AP50:95 to measure the performance of the method, which poses a further challenge to the high accuracy of the detector.
Authors
Download
- OHD-SJTU: Baidu Drive (n5aw), [Hugging Face] - OHD-SJTU-L
- OHD-SJTU-S
- Development kit
- readme.txt
Example Images
Each object is labeled by an arbitrary quadrilateral, and the first marked point is the head position of the object to facilitate the head prediction.


Baseline Methods
We divide the training and validation images into 600x600 subimages with an overlap of 150 pixels and scale it to 800x800. In the process of cropping the image with the sliding window, keeping those objects whose center point is in the subimage. All experiments are based on the same setting, using ResNet101 as the backbone. Except for data augmentation (include random horizontal, vertical flipping, random graying, and random rotation) is used in OHD-SJTU-S, no other tricks are used.
Performance on OBB task of OHD-SJTU-L:
| Method | PL | SH | SV | LV | HA | HC | AP50 | AP75 | AP50:95 |
|---|---|---|---|---|---|---|---|---|---|
| R2CNN | 89.99 | 71.93 | 54.00 | 65.46 | 66.36 | 55.94 | 67.28 | 32.69 | 34.78 |
| RRPN | 89.66 | 75.35 | 50.25 | 72.22 | 62.99 | 45.26 | 65.96 | 21.24 | 30.13 |
| RetinaNet-H | 90.20 | 66.99 | 53.58 | 63.38 | 63.75 | 53.82 | 65.29 | 34.59 | 35.39 |
| RetinaNet-R | 89.99 | 77.65 | 51.77 | 81.22 | 62.85 | 52.25 | 69.29 | 39.07 | 38.90 |
| R3Det | 89.89 | 78.36 | 55.23 | 78.35 | 57.06 | 53.50 | 68.73 | 35.36 | 37.10 |
| OHDet | 89.72 | 77.40 | 52.89 | 78.72 | 63.76 | 54.62 | 69.52 | 41.89 | 39.51 |
Performance on OBB task of OHD-SJTU-S:
| Method | PL | SH | AP50 | AP75 | AP50:95 |
|---|---|---|---|---|---|
| R2CNN | 90.91 | 77.66 | 84.28 | 55.00 | 52.80 |
| RRPN | 90.14 | 76.13 | 83.13 | 27.87 | 40.74 |
| RetinaNet-H | 90.86 | 66.32 | 78.59 | 58.45 | 53.07 |
| RetinaNet-R | 90.82 | 88.14 | 89.48 | 74.62 | 61.86 |
| R3Det | 90.82 | 85.59 | 88.21 | 67.13 | 56.19 |
| OHDet | 90.74 | 87.59 | 89.06 | 78.55 | 63.94 |
The performance of object heading detection on OHD-SJTU-L:
| Task | PL | SH | SV | LV | HA | HC | IoU50 | IoU75 | IoU50:95 |
|---|---|---|---|---|---|---|---|---|---|
| OBB mAP | 89.63 | 75.88 | 46.21 | 75.88 | 61.43 | 33.87 | 63.88 | 37.45 | 36.42 |
| OHD mAP | 59.88 | 41.90 | 26.21 | 35.34 | 41.24 | 17.53 | 37.02 | 24.10 | 22.46 |
| Head Accuracy | 74.49 | 69.71 | 62.21 | 57.95 | 76.66 | 49.06 | 65.01 | 65.77 | 64.60 |
The performance of object heading detection on OHD-SJTU-S:
| Task | PL | SH | IoU50 | IoU75 | IoU50:95 |
|---|---|---|---|---|---|
| OBB mAP | 90.73 | 88.59 | 89.66 | 75.62 | 61.49 |
| OHD mAP | 76.89 | 86.40 | 81.65 | 65.51 | 55.09 |
| Head Accuracy | 90.91 | 94.87 | 92.89 | 93.81 | 94.25 |